Publications
2024
-
 Reasoning with trees: interpreting CNNs using hierarchiesCaroline Mazini Rodrigues , Nicolas Boutry , and Laurent NajmanArxiv, 2024
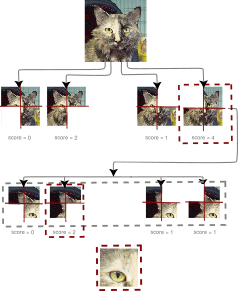
Reasoning with trees: interpreting CNNs using hierarchiesCaroline Mazini Rodrigues , Nicolas Boutry , and Laurent NajmanArxiv, 2024Challenges persist in providing interpretable explanations for neural network reasoning in explainable AI (xAI). Existing methods like Integrated Gradients produce noisy maps, and LIME, while intuitive, may deviate from the model’s reasoning. We introduce a framework that uses hierarchical segmentation techniques for faithful and interpretable explanations of Convolutional Neural Networks (CNNs). Our method constructs model-based hierarchical segmentations that maintain the model’s reasoning fidelity and allows both human-centric and model-centric segmentation. This approach offers multiscale explanations, aiding bias identification and enhancing understanding of neural network decision-making. Experiments show that our framework, xAiTrees, delivers highly interpretable and faithful model explanations, not only surpassing traditional xAI methods but shedding new light on a novel approach to enhancing xAI interpretability. Code at: https://github.com/CarolMazini/reasoning_with_trees.
@article{rodrigues:2024:Arxiv, title = {Reasoning with trees: interpreting CNNs using hierarchies}, author = {Rodrigues, Caroline Mazini and Boutry, Nicolas and Najman, Laurent}, journal = {Arxiv}, pages = {}, year = {2024}, volume = {}, publisher = {}, doi = {}, } -
 Unsupervised discovery of Interpretable Visual ConceptsCaroline Mazini Rodrigues , Nicolas Boutry , and Laurent NajmanInformation Sciences, 2024
Unsupervised discovery of Interpretable Visual ConceptsCaroline Mazini Rodrigues , Nicolas Boutry , and Laurent NajmanInformation Sciences, 2024Providing interpretability of deep-learning models to non-experts, while fundamental for a responsible real-world usage, is challenging. Attribution maps from xAI techniques, such as Integrated Gradients, are a typical example of a visualization technique containing a high level of information, but with difficult interpretation. In this paper, we propose two methods, Maximum Activation Groups Extraction (MAGE) and Multiscale Interpretable Visualization (Ms-IV), to explain the model’s decision, enhancing global interpretability. MAGE finds, for a given CNN, combinations of features which, globally, form a semantic meaning, that we call concepts. We group these similar feature patterns by clustering in “concepts”, that we visualize through Ms-IV. This last method is inspired by Occlusion and Sensitivity analysis (incorporating causality) and uses a novel metric, called Class-aware Order Correlation (CAOC), to globally evaluate the most important image regions according to the model’s decision space. We compare our approach to xAI methods such as LIME and Integrated Gradients. Experimental results evince the Ms-IV higher localization and faithfulness values. Finally, qualitative evaluation of combined MAGE and Ms-IV demonstrates humans’ ability to agree, based on the visualization, with the decision of clusters’ concepts; and, to detect, among a given set of networks, the existence of bias.
@article{rodrigues:2024:if, title = {Unsupervised discovery of Interpretable Visual Concepts}, author = {Rodrigues, Caroline Mazini and Boutry, Nicolas and Najman, Laurent}, journal = {Information Sciences}, pages = {120159}, year = {2024}, volume = {661}, publisher = {Elsevier}, doi = {10.1016/j.ins.2024.120159}, } -
 Transforming gradient-based techniques into interpretable methodsCaroline Mazini Rodrigues , Nicolas Boutry , and Laurent NajmanPattern Recognition Letters, 2024
Transforming gradient-based techniques into interpretable methodsCaroline Mazini Rodrigues , Nicolas Boutry , and Laurent NajmanPattern Recognition Letters, 2024The explication of Convolutional Neural Networks (CNN) through xAI techniques often poses challenges in interpretation. The inherent complexity of input features, notably pixels extracted from images, engenders complex correlations. Gradient-based methodologies, exemplified by Integrated Gradients (IG), effectively demonstrate the significance of these features. Nevertheless, the conversion of these explanations into images frequently yields considerable noise. Presently, we introduce GAD (Gradient Artificial Distancing) as a supportive framework for gradient-based techniques. Its primary objective is to accentuate influential regions by establishing distinctions between classes. The essence of GAD is to limit the scope of analysis during visualization and, consequently reduce image noise. Empirical investigations involving occluded images have demonstrated that the identified regions through this methodology indeed play a pivotal role in facilitating class differentiation.
@article{rodrigues:2024:PRL, title = {Transforming gradient-based techniques into interpretable methods}, author = {Rodrigues, Caroline Mazini and Boutry, Nicolas and Najman, Laurent}, journal = {Pattern Recognition Letters}, pages = {}, year = {2024}, publisher = {}, doi = {10.1016/j.patrec.2024.06.006}, }



2023
-
 Bridging Human Concepts and Computer Vision for Explainable Face VerificationMiriam Doh , Caroline Mazini Rodrigues , Nicolas Boutry , and 3 more authorsIn 2nd Workshop on Bias, Ethical AI, Explainability and the role of Logic and Logic Programming co-located with the 22nd International Conference of the Italian Association for Artificial Intelligence (AI*IA 2023) , 2023
Bridging Human Concepts and Computer Vision for Explainable Face VerificationMiriam Doh , Caroline Mazini Rodrigues , Nicolas Boutry , and 3 more authorsIn 2nd Workshop on Bias, Ethical AI, Explainability and the role of Logic and Logic Programming co-located with the 22nd International Conference of the Italian Association for Artificial Intelligence (AI*IA 2023) , 2023With Artificial Intelligence (AI) influencing the decision-making process of sensitive applications such as Face Verification, it is fundamental to ensure the transparency, fairness, and accountability of decisions. Although Explainable Artificial Intelligence (XAI) techniques exist to clarify AI decisions, it is equally important to provide interpretability of these decisions to humans. In this paper, we present an approach to combine computer and human vision to increase the explanation’s interpretability of a face verification algorithm. In particular, we are inspired by the human perceptual process to understand how machines perceive face’s human-semantic areas during face comparison tasks. We use Mediapipe, which provides a segmentation technique that identifies distinct human-semantic facial regions, enabling the machine’s perception analysis. Additionally, we adapted two model-agnostic algorithms to provide human-interpretable insights into the decision-making processes.
@inproceedings{doh:2024:beware, title = {Bridging Human Concepts and Computer Vision for Explainable Face Verification }, author = {Doh, Miriam and Rodrigues, Caroline Mazini and Boutry, Nicolas and Najman, Laurent and Mancas, Matei and Bersini, Hugues}, booktitle = {2nd Workshop on Bias, Ethical AI, Explainability and the role of Logic and Logic Programming co-located with the 22nd International Conference of the Italian Association for Artificial Intelligence (AI*IA 2023)}, pages = {15--29}, year = {2023}, publisher = {CEUR-WS.org}, doi = {hal-04416562}, volume = {3615}, }

2021
-
 Manifold learning for real-world event understandingCaroline Mazini Rodrigues , Aurea Soriano-Vargas , Bahram Lavi , and 2 more authorsIEEE Transactions on Information Forensics and Security, 2021
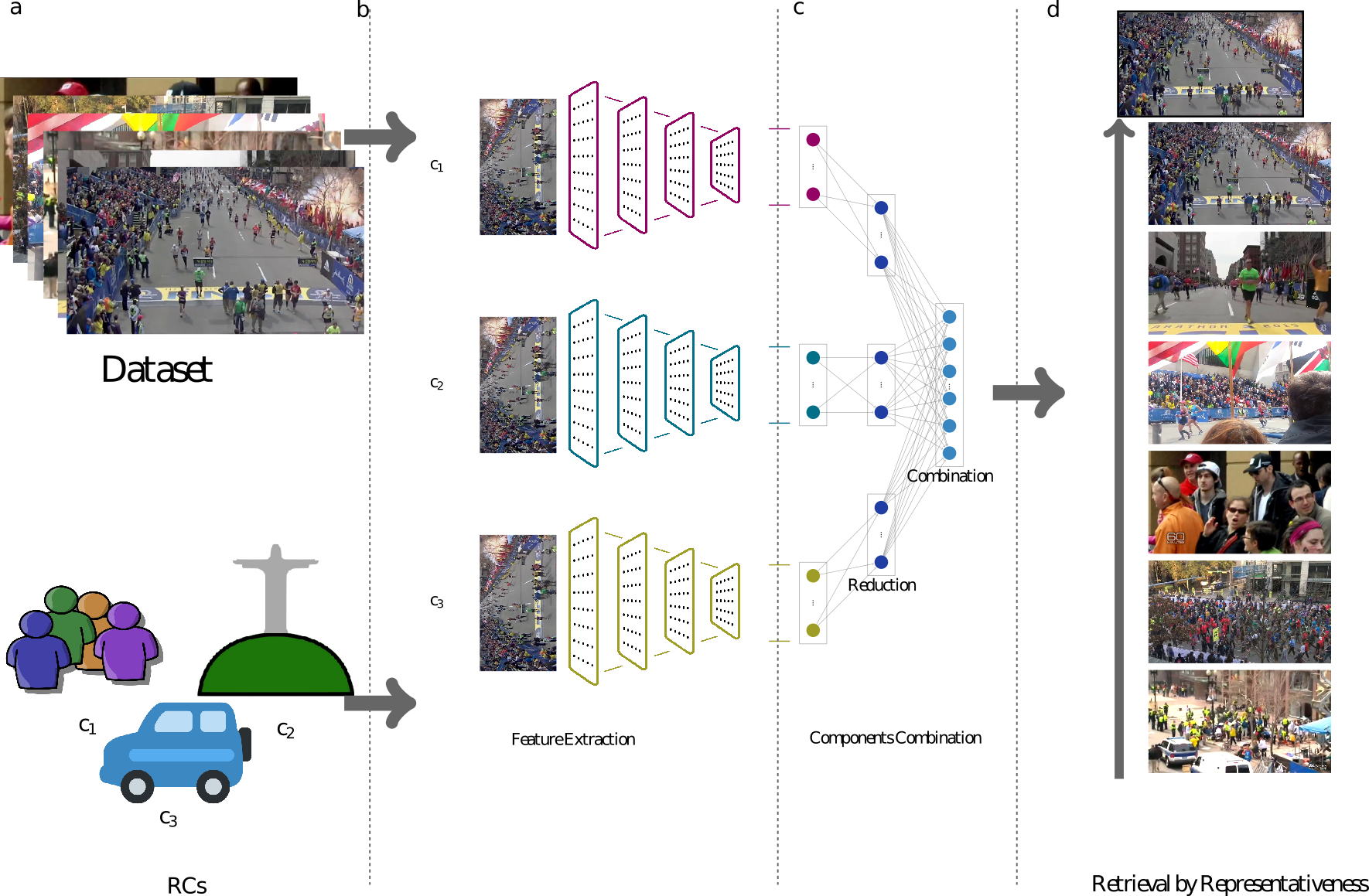
Manifold learning for real-world event understandingCaroline Mazini Rodrigues , Aurea Soriano-Vargas , Bahram Lavi , and 2 more authorsIEEE Transactions on Information Forensics and Security, 2021Information coming from social media is vital to the understanding of the dynamics involved in multiple events such as terrorist attacks and natural disasters. With the spread and popularization of cameras and the means to share content through social networks, an event can be followed through many different lenses and vantage points. However, social media data present numerous challenges, and frequently it is necessary a great deal of data cleaning and filtering techniques to separate what is related to the depicted event from contents otherwise useless. In a previous effort of ours, we decomposed events into representative components aiming at describing vital details of an event to characterize its defining moments. However, the lack of minimal supervision to guide the combination of representative components somehow limited the performance of the method. In this paper, we extend upon our prior work and present a learning-from-data method for dynamically learning the contribution of different components for a more effective event representation. The method relies upon just a few training samples (few-shot learning), which can be easily provided by an investigator. The obtained results on real-world datasets show the effectiveness of the proposed ideas.
@article{rodrigues:2021:tifs, title = {Manifold learning for real-world event understanding}, author = {Rodrigues, Caroline Mazini and Soriano-Vargas, Aurea and Lavi, Bahram and Rocha, Anderson and Dias, Zanoni}, journal = {IEEE Transactions on Information Forensics and Security}, volume = {16}, pages = {2957--2972}, year = {2021}, publisher = {IEEE}, doi = {10.1109/TIFS.2021.3070431}, }

2020
-
 Forensic event analysis: From seemingly unrelated data to understandingRafael Padilha , Caroline Mazini Rodrigues , Fernanda Alcantara Andalo , and 3 more authorsIEEE Security & Privacy, 2020
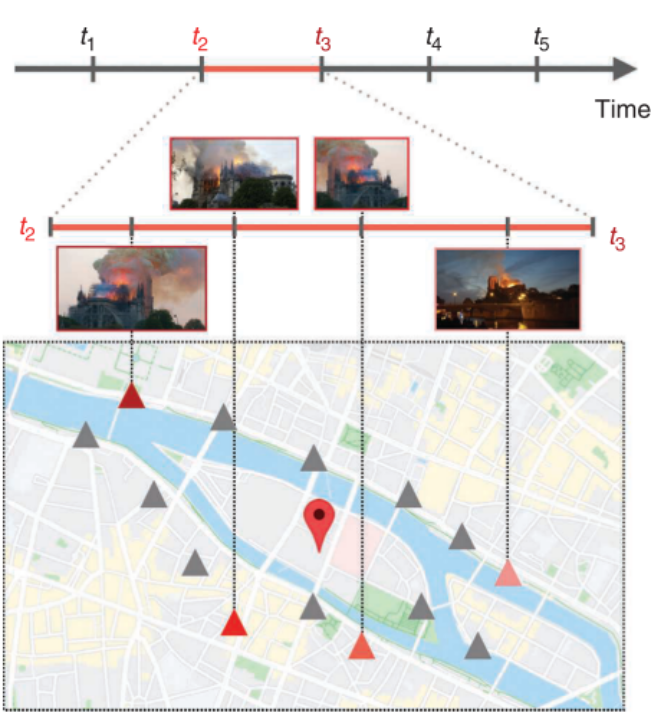
Forensic event analysis: From seemingly unrelated data to understandingRafael Padilha , Caroline Mazini Rodrigues , Fernanda Alcantara Andalo , and 3 more authorsIEEE Security & Privacy, 2020We discuss the problem of restructuring visual data from different heterogeneous sources to analyze an event of interest. We present X-coherence: a pipeline seeking to organize and represent pieces of data, tying them coherently with the real world and with one another. We also outline research challenges while seeking X-coherence.
@article{padilha:2020:sp, title = {Forensic event analysis: From seemingly unrelated data to understanding}, author = {Padilha, Rafael and Rodrigues, Caroline Mazini and Andalo, Fernanda Alcantara and Bertocco, Gabriel and Dias, Zanoni and Rocha, Anderson}, journal = {IEEE Security \& Privacy}, volume = {18}, number = {6}, pages = {23--32}, year = {2020}, publisher = {IEEE}, doi = {10.1109/MSEC.2020.3000446}, }

2019
-
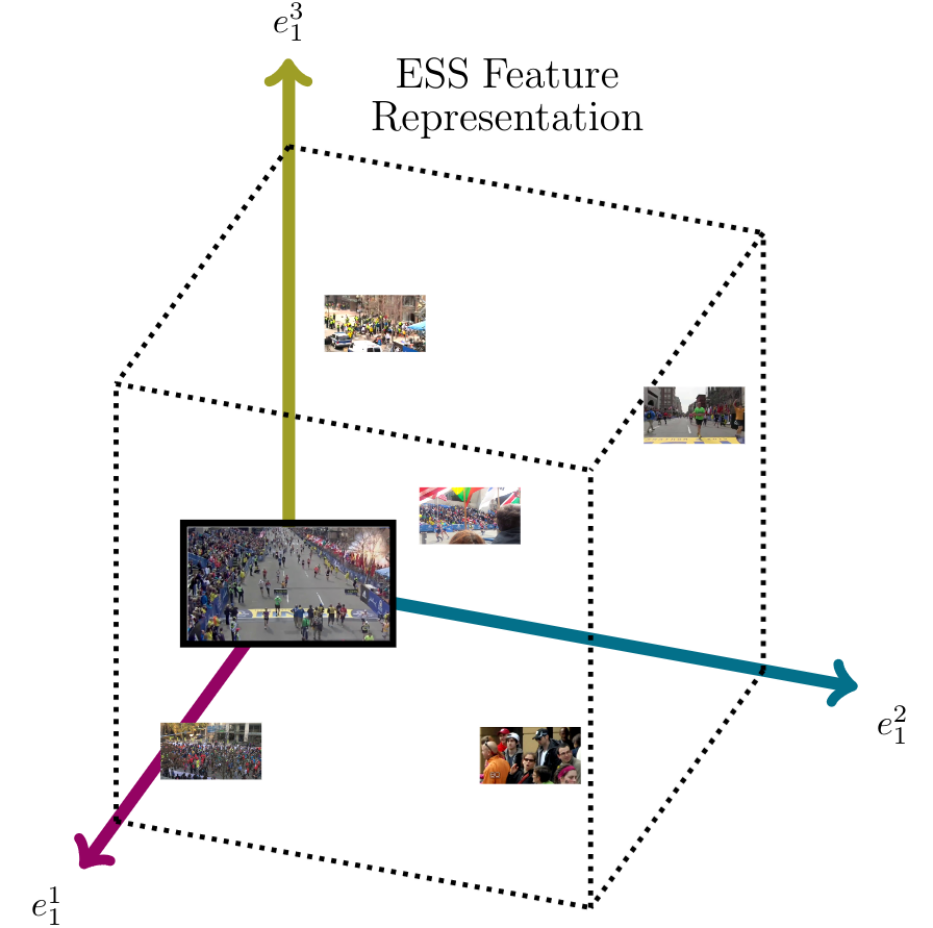 Image Semantic Representation for Event UnderstandingCaroline Mazini Rodrigues , Luis Pereira , Anderson Rocha , and 1 more authorIn 2019 IEEE International Workshop on Information Forensics and Security (WIFS) , 2019
Image Semantic Representation for Event UnderstandingCaroline Mazini Rodrigues , Luis Pereira , Anderson Rocha , and 1 more authorIn 2019 IEEE International Workshop on Information Forensics and Security (WIFS) , 2019Different events, such as terrorist acts and natural catastrophes, frequently occur across the world. The availability of images on the internet can help to understand events. However, manually selecting representative (helpful) images from a massive amount of data can be infeasible. Here, we propose an image semantic representation method that helps to understand the discrimination of Representative Images (RI) from Non-representative Images (NRI). Our method, called Event Semantic Space (ESS), generates a low-dimensional image representation by exploiting the semantics of some images with high representativeness and some representative components of the events (e.g., places, objects, and people). Results on three real-world events attest the capability of our method to represent events, outperforming three image descriptors individually in ranking tasks and presenting capability of learning patterns of Representative Images.
@inproceedings{rodrigues:2019:wifs, author = {Rodrigues, Caroline Mazini and Pereira, Luis and Rocha, Anderson and Dias, Zanoni}, booktitle = {2019 IEEE International Workshop on Information Forensics and Security (WIFS)}, title = {Image Semantic Representation for Event Understanding}, year = {2019}, volume = {}, number = {}, pages = {1-6}, keywords = {Feature extraction;Semantics;Videos;Image representation;Task analysis;Visualization;Buildings}, doi = {10.1109/WIFS47025.2019.9035102}, }
